Flaky-Test Triage Agent: A Practical QA Guide
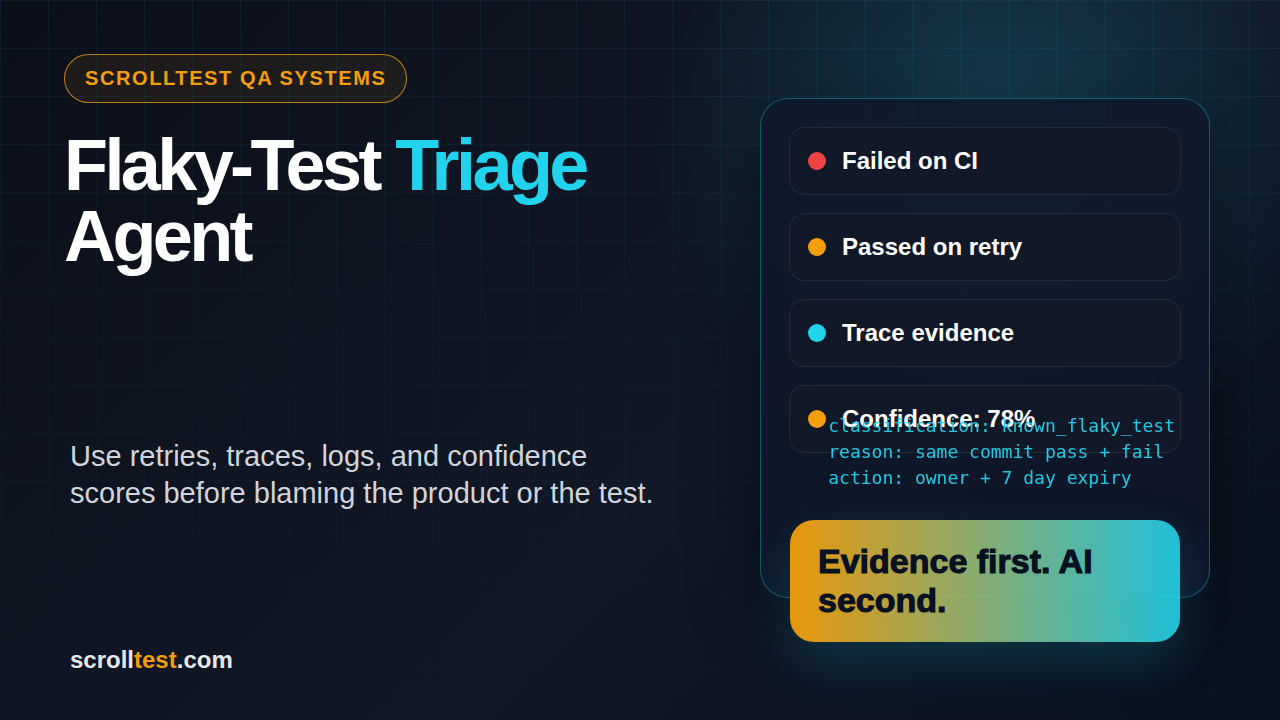
I see teams make the same mistake with every flaky-test triage agent: they ask the agent to declare truth from one failed CI run. That is not triage. That is a confident guess with a nicer UI.
🤖 Learning AI-powered testing? Go hands-on with LLM, RAG, and AI-agent testing in the AI-Powered Testing Mastery course at The Testing Academy.
A useful agent works like a disciplined QA lead. It collects retry history, compares traces, checks recent code changes, separates product failures from environment noise, and gives a confidence score that a human can challenge. This guide shows how to build that kind of system without lying to yourself.
Table of Contents
- What Is a Flaky-Test Triage Agent?
- Why Flakiness Hurts More Than Teams Admit
- The Evidence Model: What the Agent Must Collect
- Flaky-Test Triage Agent Architecture
- A TypeScript Implementation You Can Start With
- Confidence Scores Without Fake Certainty
- Using Playwright Traces, Retries, and Reports
- CI Workflow and Human Review
- India QA Team Context
- Key Takeaways
- FAQ
Contents
What Is a Flaky-Test Triage Agent?
A flaky-test triage agent is a small decision system that reviews failed automated tests and suggests the most likely reason for each failure. It does not fix the test by magic. It classifies the failure, attaches evidence, and routes the next action to the right owner.
The important word is triage. In a hospital, triage does not mean final diagnosis. It means prioritization based on the evidence available now. The same idea applies to test automation. The agent should answer four questions before anyone touches code:
- Did this test pass and fail against the same application revision?
- Did the failure reproduce on retry?
- What changed near the failure: app code, test code, data, browser version, service dependency, or infrastructure?
- What visible evidence supports the classification?
A good agent is boring on purpose
The best version of this system is not flashy. It reads logs, pulls artifacts, compares runs, and writes a short report. If the agent cannot find evidence, it must say so. That single behavior saves a team from the worst failure mode in AI assisted QA: confident nonsense.
What it should classify
I like a small taxonomy because engineers actually use it. Start with these labels:
- Likely product bug: failure reproduces, trace shows broken behavior, and recent app changes match the failed area.
- Likely test bug: selector, assertion, data setup, or timing assumption is weak.
- Likely environment issue: service outage, browser crash, network timeout, queue delay, or test runner instability.
- Known flaky test: history shows intermittent pass and fail on the same revision.
- Unknown: not enough evidence. Human review required.
The last label matters. If the agent never says unknown, it is not trustworthy.
Why Flakiness Hurts More Than Teams Admit
Flaky tests create two costs. The visible cost is reruns and Slack noise. The hidden cost is trust decay. Once developers believe the suite cries wolf, they stop treating red builds as serious signals.
Google’s Testing Blog described this problem years ago with painful numbers: Google saw about 1.5% of all test runs reporting a flaky result, almost 16% of tests having some level of flakiness, and about 84% of pass-to-fail transitions involving flaky tests. The exact numbers will vary by team, but the pattern is familiar to anyone who watches CI every day.
The suite becomes political
When a regression suite is trusted, a red build starts a technical discussion. When the suite is flaky, a red build starts a negotiation. One developer says the test is bad. One tester says the feature is broken. A manager asks for another rerun. Nobody is looking at evidence yet.
A triage agent should reduce that drama. It should not decide who is right. It should put the relevant facts in one place: last 20 runs, retry outcome, failing step, screenshot, trace, changed files, browser version, environment, and owner.
Retries are useful but dangerous
Playwright documents retries as a way to automatically re-run a failed test, and it separates outcomes into passed, flaky, and failed. That classification is useful. It becomes dangerous when teams treat retry pass as success and never investigate the original failure.
If a payment test fails once, passes once, and the team ships without reading the trace, the retry has hidden risk. A good flaky-test triage agent treats retry pass as evidence of intermittency, not proof that everything is fine.
The failure budget is real
Here is a simple way to calculate the cost. If 12 engineers lose 12 minutes a day checking false failures, that is 144 minutes per day. Across 22 working days, that is more than 52 engineering hours per month. In India, where many QA teams support both local and US time zones, these failures often happen during handoff hours. That makes the delay feel even worse.
The Evidence Model: What the Agent Must Collect
Do not start with an LLM prompt. Start with an evidence model. If the data is weak, the summary will be weak. The agent should collect structured facts first and ask the model to summarize only after the facts are available.
Minimum data for one failed test
For every failed test, store these fields:
- Test title, file, line number, project, browser, and shard
- Commit SHA, branch, pull request, author, and changed files
- Run ID, job ID, retry number, worker number, and duration
- Error message, stack trace, assertion text, and failed step
- Screenshot, video, trace zip, console logs, network errors, and HAR when available
- Last N outcomes for the same test on the same branch and on main
- Environment health signals such as deployment status, API latency, and incident flags
This looks basic. That is the point. Most AI triage demos fail because they summarize the error message but ignore run history and environment context.
History beats one screenshot
A screenshot is helpful, but history is stronger. A test that failed once after 40 clean runs deserves different treatment from a test that failed 9 times in the last 30 runs. The agent should compute a flakiness window instead of guessing.
{
"testId": "checkout.spec.ts::guest checkout applies coupon",
"window": 30,
"pass": 21,
"fail": 7,
"skipped": 2,
"distinctCommitsWithBothPassAndFail": 4,
"lastFailureStep": "expect(page.getByText('Order placed')).toBeVisible()",
"classification": "known_flaky_candidate"
}Root cause hints are not root causes
The agent can produce hints like “selector instability” or “backend timeout.” It should not claim root cause unless the evidence proves it. The pytest documentation is clear that flaky tests often involve uncontrolled system state, ordering, global state, timing, and parallel execution. Those are patterns, not final answers.
I use this rule: the agent can assign a root cause only when it can name the exact artifact that proves it. A console error, a 500 response, a missing DOM node, a changed selector, or a timeout histogram can support a claim. A vague “probably timing issue” cannot.
Flaky-Test Triage Agent Architecture
A practical flaky-test triage agent has five parts. Keep them separate. If you mix collection, reasoning, and action in one script, debugging the agent becomes harder than debugging the flaky test.
1. Artifact collector
This component downloads Playwright reports, trace files, screenshots, videos, CI logs, and test result JSON. It should be deterministic and boring. No AI here.
2. History store
This can be PostgreSQL, SQLite, BigQuery, S3 plus Athena, or even a JSON file for a pilot. The key is stable test identity. Do not identify a test only by title because titles change. Store file path, test title path, project, and a hash.
3. Feature extractor
This layer converts raw artifacts into signals. Examples:
- Retry passed after original failure
- Same commit has both pass and fail
- Error includes timeout waiting for locator
- Trace contains failed network call
- Failure only appears on WebKit or mobile viewport
- Failure started after a specific test file changed
4. Reasoning layer
This is where rules and an LLM can work together. I prefer rules first, model second. Rules are better for hard signals. The model is better for summarizing messy logs and writing a short explanation for humans.
5. Workflow adapter
The adapter sends the output to GitHub, Slack, Jira, Linear, or a dashboard. It should create a compact triage note, not a wall of text. If the note takes longer to read than the trace, people stop reading it.
If your team is already exploring AI test agents, read AI Test Agents Need a Planner, Generator, and Healer. The same separation of responsibilities applies here. The triage agent should not be a giant prompt pretending to be a system.
A TypeScript Implementation You Can Start With
Below is a small TypeScript version. It is intentionally simple. You can run it after a Playwright job, feed it test results, and produce a triage summary. The goal is to show the shape of the system, not a full SaaS product.
Step 1: Define the data types
type TestOutcome = 'passed' | 'failed' | 'flaky' | 'skipped';
type FailedRun = {
testId: string;
title: string;
file: string;
project: string;
commit: string;
branch: string;
runId: string;
retry: number;
errorMessage: string;
failedStep?: string;
tracePath?: string;
screenshotPath?: string;
changedFiles: string[];
networkErrors: string[];
durationMs: number;
};
type HistoricalStats = {
window: number;
pass: number;
fail: number;
flaky: number;
sameCommitPassAndFail: boolean;
lastFailedAt?: string;
};
type TriageResult = {
label: 'likely_product_bug' | 'likely_test_bug' | 'likely_environment_issue' | 'known_flaky_test' | 'unknown';
confidence: number;
reasons: string[];
nextAction: string;
};Step 2: Add rule-based classification
function classifyFailure(run: FailedRun, history: HistoricalStats): TriageResult {
const reasons: string[] = [];
let score = 0;
if (history.sameCommitPassAndFail || history.flaky > 0) {
reasons.push('Same test has pass and fail evidence in the recent window.');
score += 35;
}
if (/Timeout|waiting for locator|toBeVisible/i.test(run.errorMessage)) {
reasons.push('Failure text points to a waiting or selector problem.');
score += 20;
}
if (run.networkErrors.some(e => /ECONNRESET|502|503|504|timeout/i.test(e))) {
reasons.push('Network errors appeared during the failed run.');
return {
label: 'likely_environment_issue',
confidence: Math.min(85, 50 + score),
reasons,
nextAction: 'Check service health and rerun after dependency recovery.'
};
}
const testFileChanged = run.changedFiles.some(f => f === run.file || f.includes('/tests/'));
if (testFileChanged) {
reasons.push('Test code changed in the same pull request.');
return {
label: 'likely_test_bug',
confidence: Math.min(80, 45 + score),
reasons,
nextAction: 'Review selector, data setup, and assertion changes before blaming product code.'
};
}
if (history.sameCommitPassAndFail) {
return {
label: 'known_flaky_test',
confidence: Math.min(90, score),
reasons,
nextAction: 'Quarantine only with owner and expiry date. Create a fix ticket with trace evidence.'
};
}
return {
label: 'unknown',
confidence: Math.min(55, score),
reasons: reasons.length ? reasons : ['Not enough evidence to classify safely.'],
nextAction: 'Human review required. Open trace and compare with last passing run.'
};
}Step 3: Write a human-readable note
function formatTriageNote(run: FailedRun, result: TriageResult): string {
return [
`### Triage: ${run.title}`,
`Label: ${result.label}`,
`Confidence: ${result.confidence}%`,
`Run: ${run.runId}`,
`Project: ${run.project}`,
'',
'Evidence:',
...result.reasons.map(r => `- ${r}`),
'',
`Next action: ${result.nextAction}`,
run.tracePath ? `Trace: ${run.tracePath}` : '',
run.screenshotPath ? `Screenshot: ${run.screenshotPath}` : ''
].filter(Boolean).join('\n');
}This is enough to start. Later you can add embeddings for similar failures, LLM summaries, and automatic Jira routing. But do not skip the rule layer. It is the spine of the system.
🚀 Build Real AI Testing Skills
Stop testing AI by guesswork. Learn DeepEval, RAG evaluation, and agent testing with guided projects.
Confidence Scores Without Fake Certainty
Confidence scoring is where many AI QA tools overpromise. A score of 92% looks scientific even when it came from a prompt. That is not acceptable for CI decisions.
Use evidence-weighted scoring
Build confidence from observable signals. For example:
- Same commit has pass and fail: +35
- Failure passed on retry: +20 for flakiness, not for success
- Known service incident during run: +30 for environment issue
- Test file changed in PR: +25 for test bug
- Application file in failed feature changed: +20 for product bug
- No trace or screenshot: cap confidence at 60
- No history available: cap confidence at 55
The caps are as important as the points. If there is no history, the system should not claim high certainty. If there is no trace, it should not pretend to know what happened in the browser.
Separate label confidence from action confidence
The agent may be 80% confident that a test is flaky and only 40% confident about the right fix. Keep those separate. A flaky label tells you the signal is unreliable. It does not automatically tell you whether to rewrite selectors, isolate data, mock an API, or slow down a backend dependency.
Make disagreement cheap
Add a one-click feedback option: correct, wrong label, missing evidence, known issue, needs owner. Store that feedback. After 30 days, you will know whether the agent is helping or producing nice-looking noise.
This is where evaluation habits from LLM testing help. If you already compare outputs with PromptFoo or DeepEval, the same thinking applies. For more context, see DeepEval vs PromptFoo: LLM Evaluation for QA Teams.
Using Playwright Traces, Retries, and Reports
Playwright gives you a strong base for this workflow. The trace viewer can inspect actions, snapshots, console messages, network activity, source code, and attachments. That is exactly the evidence a triage agent needs.
Recommended Playwright config
import { defineConfig } from '@playwright/test';
export default defineConfig({
retries: process.env.CI ? 1 : 0,
reporter: [
['html', { outputFolder: 'playwright-report' }],
['json', { outputFile: 'test-results/results.json' }]
],
use: {
trace: 'retain-on-failure',
screenshot: 'only-on-failure',
video: 'retain-on-failure'
}
});One retry is often enough to detect intermittent behavior without doubling the cost of the suite. For critical flows, you may use a different policy. The point is to make retries intentional, not automatic paint over the warning light.
What to extract from the trace
Do not send the whole trace to a model. Extract a compact summary:
- Last 10 actions before failure
- Failed assertion and locator
- Console errors and page errors
- Network responses with 4xx, 5xx, and timeouts
- URL at failure time
- Screenshot path and trace link
If you are new to Playwright’s waiting model, read Playwright Actions and Auto-Waiting. Many flaky UI tests are not caused by Playwright. They are caused by unclear readiness conditions in the app or weak assertions in the test.
Do not hide flaky tests forever
Quarantine is a pressure valve, not a retirement home. If the agent labels a test as known flaky, create an expiry date and an owner. I like 7 days for smoke tests and 14 days for non-critical regression tests. After that, the test either gets fixed, deleted, or replaced with a more reliable check.
CI Workflow and Human Review
The workflow should fit into the team’s existing CI process. Do not force engineers to open a separate dashboard for every failure. Put the first useful summary where the failure already appears.
A simple GitHub Actions flow
name: e2e
on: [pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 22
- run: npm ci
- run: npx playwright install --with-deps
- run: npx playwright test
continue-on-error: true
- run: node tools/triage-agent.js
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- uses: actions/upload-artifact@v4
with:
name: playwright-artifacts
path: |
playwright-report
test-resultsNotice the continue-on-error. The test job can finish artifact upload and triage even after failures. You can still fail the workflow at the end based on policy. The key is not losing evidence.
The triage comment format
Keep comments short:
- Test name and project
- Classification and confidence
- Three evidence bullets
- Trace and screenshot links
- Suggested owner or next action
A comment with 40 lines is ignored. A comment with five sharp bullets is read.
Where humans stay in control
The agent should not merge, revert, quarantine, or delete tests without a policy gate. It can suggest. It can open a ticket. It can label a PR. But for the first version, keep a human approval step for actions that change test coverage.
If your suite contains API checks as well as UI checks, connect the same triage workflow to API failures. Contract failures, 500 responses, and test data errors often explain UI failures faster than another browser rerun. This is one reason I like combining UI and API evidence, as covered in API Testing with AI Agents.
India QA Team Context
For QA teams in India, flaky tests are not just a technical irritation. They affect career growth and delivery perception. Many service teams work with clients who see only the final status: green or red. A noisy suite makes the team look slower even when the engineers are doing the right work.
Manual testers moving into SDET roles
If you are moving from manual testing to automation, this is a strong project for your portfolio. Do not build another login test demo. Build a small triage agent that reads Playwright JSON, detects retry pass, checks a previous run file, and writes a failure note.
That project shows practical engineering judgment. It tells interviewers you understand CI, test reliability, artifacts, and risk. For ₹25 to ₹40 LPA SDET roles in product companies, this is more useful than saying you know five tools by name.
Service company reality
In TCS, Infosys, Wipro, Cognizant, or similar delivery environments, you may not get permission to add a full AI workflow to client CI. Start smaller. Build a local report that consumes exported artifacts. Show before and after numbers:
- Average time to identify flaky failures
- Number of repeated reruns per week
- Top 10 flaky tests by failure rate
- Tests quarantined with owner and expiry
- False triage rate after human review
Managers listen when you reduce wasted time and make risk visible.
Key Takeaways
A flaky-test triage agent is useful only when it respects evidence. The goal is not to make CI look green. The goal is to protect the signal of the test suite.
- Start with structured evidence: run history, retries, traces, logs, screenshots, and changed files.
- Use rules for hard signals and an LLM only for summaries or messy log interpretation.
- Confidence scores need caps. No trace, no history, no high confidence.
- Retries show intermittency. They do not prove the product is safe.
- Quarantine must have an owner and expiry date, or it becomes silent test deletion.
If you build this well, your team spends less time arguing about red builds and more time fixing real reliability problems.
FAQ
Should a flaky-test triage agent automatically quarantine tests?
Not in the first version. Let it recommend quarantine with evidence. Add automatic quarantine only after you have measured false labels for a few weeks and added owner, expiry, and review rules.
Can I build this without an LLM?
Yes. A rule-based version is already valuable. Start with retry history, same-commit pass/fail detection, network errors, and changed files. Add an LLM later for summarizing logs and writing cleaner PR comments.
How many retries should I use?
For many Playwright suites, one CI retry is a reasonable start. More retries can hide risk and increase runtime. Use retries to collect evidence, not to pretend the first failure never happened.
What is the best first metric?
Track mean time to classification. If failures used to take 30 minutes to sort and now take 8 minutes with evidence attached, the agent is helping. Also track wrong classification rate from human feedback.
What should I avoid?
Avoid a giant prompt that reads one error message and declares root cause. Also avoid permanent quarantine, unowned flaky tests, and confidence scores that do not show evidence. Those patterns make the suite less trustworthy.
Sources: Google Testing Blog on flaky tests at Google, Playwright documentation on retries, Playwright Trace Viewer documentation, pytest documentation on flaky tests, and npm download data for Playwright packages.
🎓 Become an AI-Powered QA Engineer
Join hundreds of SDETs mastering LLM, RAG, and agent testing. Lifetime access, hands-on labs, and a job-ready portfolio.