LLM Output Evaluation for QA Engineers: Day 5
Most QA interviews are changing. The new question is not only “Can you automate this flow?” It is “Can you evaluate an LLM output without getting fooled by confidence?” In Day 5 of the 100 Days of AI in QA and SDET series, I show the skill that separates prompt users from AI-ready SDETs.
🤖 Learning AI-powered testing? Go hands-on with LLM, RAG, and AI-agent testing in the AI-Powered Testing Mastery course at The Testing Academy.
Table of Contents
- What Is LLM Output Evaluation?
- Why QA Engineers Should Care About LLM Output Evaluation
- The 3 Signals I Check in Every LLM Answer
- Build a Practical Eval Rubric for QA Work
- PromptFoo Example for Regression Checks
- DeepEval Example for Python SDETs
- Interview Playbook: How to Answer This Question
- India Career Context for SDETs
- Common Mistakes When Evaluating AI Outputs
- Key Takeaways
- FAQ
Contents
What Is LLM Output Evaluation?
LLM output evaluation is the practice of checking whether an AI response is correct, useful, safe, and consistent for a specific task. It is not the same as reading an answer and saying, “Looks good.” That is only a vibe check. QA work needs evidence.
If a tester asks an AI model to generate test cases for a payment flow, the output may look polished. It may include positive scenarios, negative scenarios, edge cases, and a neat table. But that does not prove the answer covers the requirement. It also does not prove the model did not invent behavior that the product never promised.
That is why LLM output evaluation matters. It turns fuzzy AI judgement into repeatable checks. I want to know three things:
- Did the model answer the actual user request?
- Did it preserve facts from the source requirement?
- Can the answer be checked again tomorrow with the same rubric?
PromptFoo describes itself as an open-source CLI and library for evaluating and red-teaming LLM apps. Its documentation highlights matrix views, metrics, command-line usage, and CI/CD support for comparing prompts and outputs. That is very close to how QA teams already think about regression testing.
DeepEval takes a Python-first route. Its quickstart shows a small test case, a metric, and the deepeval test run command. The docs frame an LLM test case as a unit of LLM app interaction with fields like input, actual output, and expected output. Again, this should feel familiar to a tester.
Evaluation is not prompt engineering
Prompt engineering asks, “How do I get a better answer?” Evaluation asks, “How do I prove this answer is acceptable?” Both are useful, but they are different skills. A QA engineer who only improves prompts becomes dependent on trial and error. A QA engineer who builds evals creates a safety net.
Evaluation is not only for AI products
You do not need to work on ChatGPT-style products to use this skill. If your team uses AI to generate test cases, summarize bugs, classify support tickets, draft API checks, or create Playwright specs, you already have LLM outputs in your workflow. Those outputs need testing.
Why QA Engineers Should Care About LLM Output Evaluation
QA engineers should care about LLM output evaluation because AI is now part of the software delivery chain. A wrong AI answer can create weak tests, false bug reports, missed compliance checks, or broken automation code. The damage may not show up as a compiler error. It shows up as false confidence.
I see teams make the same mistake: they treat AI-generated assets as drafts, but then those drafts quietly become production inputs. A generated test suite gets merged. A generated bug summary goes to a product manager. A generated SQL validation query runs in a staging pipeline. Nobody asks who tested the AI output.
This is where SDETs have an advantage. We already understand assertions, fixtures, flaky tests, pass/fail criteria, and regression evidence. LLM evaluation is a new surface area, but the testing mindset is the same.
The market is moving toward eval skills
The tooling signal is strong. GitHub API data on 13 June 2026 showed PromptFoo with 22,156 stars, DeepEval with 16,130 stars, LangChain OpenEvals with 1,071 stars, and OpenAI Evals with 18,682 stars. NPM download data for the previous month showed PromptFoo at 1,200,709 downloads and OpenEvals at 238,519 downloads. These are not tiny hobby scripts.
PromptFoo’s latest GitHub release at the time of research was 0.121.15, published on 5 June 2026. DeepEval’s latest release was v4.0.5, published on 28 May 2026. The ecosystem is active, and QA teams will need people who can make these tools useful inside delivery pipelines.
Internal reading on ScrollTest
If you want a comparison of eval tools, read DeepEval vs PromptFoo: Which LLM Evaluation Framework Should SDETs Learn First?. If your team is already experimenting with agents, pair this article with AI Test Agents Need a Planner, Generator, and Healer. For flaky automation work, I also recommend Flaky-Test Triage Agent: A Practical QA Guide.
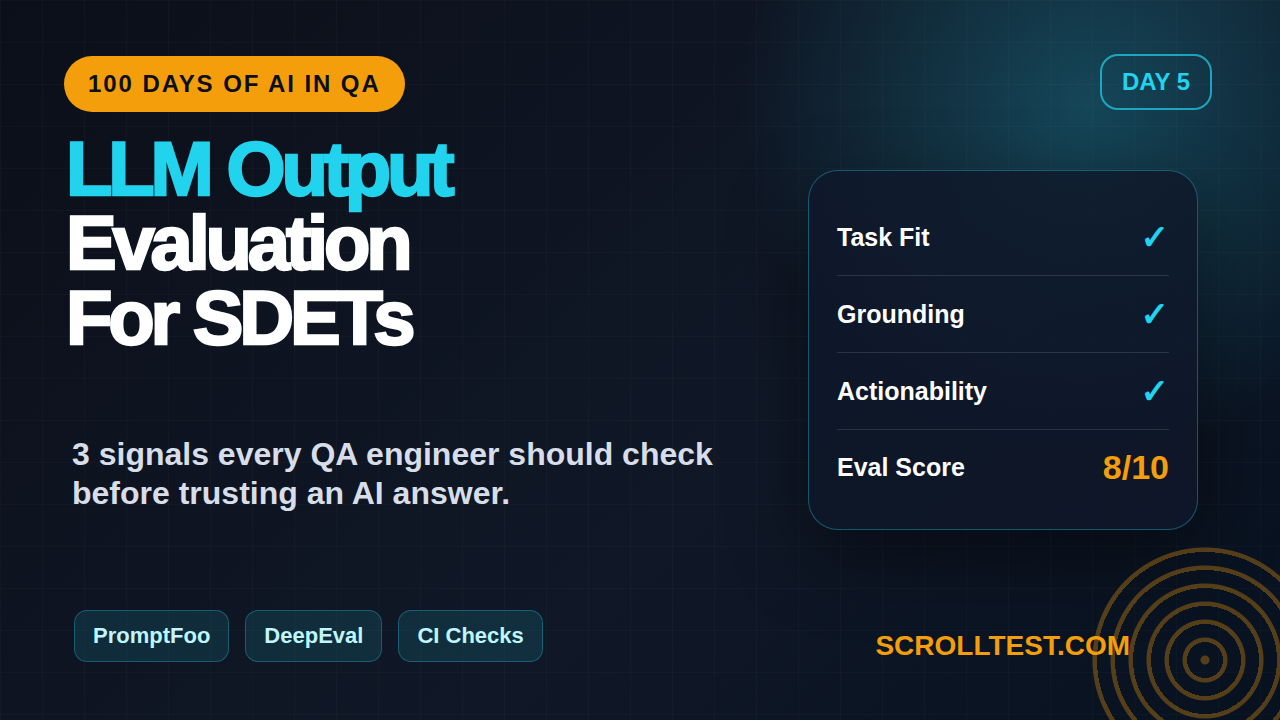
The 3 Signals I Check in Every LLM Answer
When I evaluate an LLM output, I do not start with a complex framework. I start with three signals: task fit, factual grounding, and actionability. These signals work in interviews, code reviews, QA demos, and CI checks.
Signal 1: Task fit
Task fit asks whether the answer solved the requested job. If the user asked for API test cases and the model gave UI test cases, the answer fails even if the writing is clean. If the user asked for negative cases and the model only gave happy paths, the answer fails.
I score task fit with a simple 0 to 2 scale:
- 0: Misses the request or answers a different question.
- 1: Partially answers but misses important constraints.
- 2: Answers the request and respects the constraints.
Example: requirement says “UPI payment retry is allowed once after bank timeout.” If the AI output creates three retry scenarios, it failed task fit. The answer ignored the business rule.
Signal 2: Factual grounding
Factual grounding asks whether the output stays faithful to the source material. This matters because LLMs can fill gaps with plausible text. In QA, plausible is dangerous.
For a requirement-to-test-case workflow, I check:
- Does every test case map to a requirement line?
- Does the output invent roles, statuses, APIs, or UI labels?
- Does it preserve numbers, limits, and mandatory validations?
- Does it separate assumptions from facts?
If an answer invents an “admin approval” step that does not exist in the story, I mark it down. I would rather have a shorter grounded answer than a long confident answer with two invented flows.
Signal 3: Actionability
Actionability asks whether the output helps a tester do the next step. A generic explanation is not enough. A useful AI answer should give test data, expected results, preconditions, risk notes, selectors, API fields, or executable code depending on the task.
For Playwright generation, actionability means I can run or adapt the code quickly. For bug summarization, it means the summary includes reproducible steps, actual result, expected result, environment, and evidence. For test planning, it means the output gives priority and coverage gaps.
Build a Practical Eval Rubric for QA Work
A rubric is a written scoring guide. It tells the evaluator what good looks like before the model answers. Without a rubric, every review becomes personal opinion.
Here is a simple rubric I use for AI-generated test cases:
| Criterion | Question | Score |
|---|---|---|
| Task fit | Did it answer the requested testing task? | 0-2 |
| Requirement coverage | Are critical rules covered? | 0-2 |
| No hallucination | Did it avoid invented behavior? | 0-2 |
| Negative testing | Are failure and boundary cases included? | 0-2 |
| Actionability | Can a tester execute or automate it? | 0-2 |
Total score: 10. My default threshold is 8 for human review and 9 for direct pipeline usage. I do not allow direct usage if hallucination is below 2. A single invented business rule can damage the whole suite.
How to create the rubric
Use this five-step process:
- Define the exact AI task, such as “generate API test cases from OpenAPI diff.”
- List the failure modes that would hurt your team.
- Convert each failure mode into a scoring criterion.
- Set a threshold for pass, warning, and fail.
- Run the rubric on 10 old examples before trusting it.
The last step is important. If your rubric cannot catch mistakes you already know about, it will not protect you from new mistakes.
A QA-specific rubric prompt
Evaluate this AI-generated test-case output using the rubric below.
Return JSON only.
Rubric:
- task_fit: 0, 1, or 2
- requirement_coverage: 0, 1, or 2
- no_hallucination: 0, 1, or 2
- negative_testing: 0, 1, or 2
- actionability: 0, 1, or 2
Also return:
- total_score
- failed_criteria
- evidence_lines
- improvement_suggestion
Source requirement:
{{requirement}}
AI output:
{{output}}This is not perfect, but it creates structure. You can later replace the judge prompt with PromptFoo assertions, DeepEval metrics, human annotation, or a hybrid approach.
PromptFoo Example for Regression Checks
PromptFoo is useful when you want to compare prompts, models, variables, and assertions in a repeatable way. It fits nicely into teams that already use YAML, CLI tools, and CI pipelines.
Here is a minimal example for evaluating whether an AI assistant creates grounded test cases from a requirement. This is a simplified version, not a complete enterprise setup.
# promptfooconfig.yaml
prompts:
- file://prompts/test-case-generator.txt
providers:
- openai:gpt-4.1-mini
- anthropic:messages:claude-3-5-sonnet-latest
tests:
- vars:
requirement: |
User can retry UPI payment only once after bank timeout.
Retry is not allowed after insufficient balance.
assert:
- type: contains
value: "retry only once"
- type: not-contains
value: "three retries"
- type: llm-rubric
value: |
The output must include positive, negative, and boundary test cases.
It must not invent admin approval, wallet refund, or card payment behavior.
The point is not the exact syntax. The point is the testing habit. You define inputs, expected signals, and fail conditions. Then you run the check repeatedly.
npx promptfoo@latest eval
npx promptfoo@latest viewIn a real team, I would add this to pull requests where prompts change. If the test-case generator prompt gets “improved” but starts inventing business rules, CI should catch it before the prompt reaches the team.
Where PromptFoo fits best
- Comparing multiple prompts for the same QA task.
- Checking regression when a model version changes.
- Running assertion-based checks in CI.
- Red-teaming AI features for unsafe or wrong behavior.
- Creating a simple dashboard for prompt quality discussions.
PromptFoo’s docs emphasize CLI usage, matrix views, metrics, and CI/CD. For SDETs, that means it can sit next to your existing automation pipeline instead of becoming a separate research activity.
🚀 Build Real AI Testing Skills
Stop testing AI by guesswork. Learn DeepEval, RAG evaluation, and agent testing with guided projects.
DeepEval Example for Python SDETs
DeepEval is attractive for Python-heavy QA teams. Its quickstart uses a test file, a test case, a metric, and deepeval test run. That maps well to pytest-style thinking.
Here is a practical Python example for an AI bug-summary assistant. The goal is to check whether the summary includes the important reproduction details.
from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import GEval
bug_summary_metric = GEval(
name="Bug summary quality",
criteria="""
Score the output from 0 to 1.
It must include reproducible steps, actual result, expected result,
environment, and evidence. It must not invent root cause.
""",
evaluation_params=["input", "actual_output"],
threshold=0.8,
)
def test_ai_bug_summary():
test_case = LLMTestCase(
input="""
Console error on checkout page after applying coupon SAVE10.
Chrome 126, staging, user testbuyer@example.com.
Steps: login, add product, apply coupon, click pay.
Actual: blank payment panel. Expected: payment options visible.
Screenshot and console trace attached.
""",
actual_output="""
Checkout payment panel goes blank after SAVE10 coupon on Chrome 126 staging.
Steps: login, add product, apply SAVE10, click pay.
Actual result: blank payment panel.
Expected result: payment options should remain visible.
Evidence: screenshot and console trace attached.
Root cause not confirmed.
""",
)
assert_test(test_case, [bug_summary_metric])Run it with:
pip install -U deepeval
deepeval test run test_bug_summary.pyThe strong part of this pattern is that QA engineers can express judgement in a test-like format. You still need human review for high-risk workflows, but you stop relying on random manual reading for every AI answer.
When I prefer DeepEval
- The team uses Python for automation or data testing.
- You want evals close to code.
- You need custom metrics for RAG, agents, or multi-turn flows.
- You want to test components inside an AI pipeline, not only final text.
Interview Playbook: How to Answer This Question
If an interviewer asks, “How do you evaluate an LLM output?” do not answer with “I check if it is correct.” That is too weak. Give a structured answer with a concrete example.
A strong answer structure
Use this sequence:
- Clarify the task. Ask what the LLM output is supposed to do.
- Define the rubric. Mention task fit, grounding, and actionability.
- Create a dataset. Use real examples, edge cases, and known bad outputs.
- Automate repeatable checks. Use PromptFoo, DeepEval, OpenEvals, or custom tests.
- Add human review for high-risk cases. Do not pretend automation catches everything.
- Track regression over time. Compare prompt and model changes before rollout.
That answer shows maturity. It tells the interviewer you understand both testing and AI uncertainty.
Sample interview answer
“I evaluate an LLM output the same way I evaluate a testable feature: define expected behavior, create examples, and check failures. For a test-case generator, I use a rubric with task fit, requirement coverage, no hallucination, negative coverage, and actionability. I keep a dataset of old requirements and known tricky cases. Then I run PromptFoo or DeepEval in CI when the prompt or model changes. I still keep human review for high-risk flows like payment, compliance, or security because an LLM judge can also be wrong.”
That is a much better answer than naming five AI tools. Tools change. Evaluation thinking stays useful.
India Career Context for SDETs
For Indian QA engineers, this skill is not academic. Service companies and product companies are both adding AI-assisted delivery workflows. The difference is in expectations.
In many service-company environments, the near-term ask may be productivity: generate test cases faster, summarize defects, create scripts, and reduce manual documentation work. In product companies and well-funded startups, the ask becomes stronger: evaluate AI features, test RAG quality, check agent behavior, and build eval pipelines.
If you are targeting better SDET roles, especially in Bengaluru, Hyderabad, Pune, NCR, or remote-first teams, learn to discuss evals with examples. A ₹25-40 LPA SDET role usually expects more than tool usage. It expects judgement, system thinking, and the ability to protect releases from hidden risk.
What to build for your portfolio
Create one small GitHub project:
- A sample requirement document with 10 user stories.
- An AI prompt that generates test cases.
- A PromptFoo config that checks hallucination and coverage.
- A DeepEval test for one bug-summary workflow.
- A GitHub Actions workflow that runs the evals on pull request.
- A README showing failed and passed examples.
This is more convincing than writing “AI testing” on your resume. It gives the interviewer something concrete to inspect.
Common Mistakes When Evaluating AI Outputs
The first mistake is evaluating only grammar. Clean English does not mean correct testing. I have seen beautiful test cases that missed the one business rule that mattered.
The second mistake is using only an LLM judge. LLM-as-judge can help, but it can also be inconsistent. Use deterministic assertions wherever possible: contains, not-contains, schema checks, exact fields, API status codes, and coverage IDs.
The third mistake is ignoring the dataset. If your eval dataset has only happy paths, your scores will look great and your users will still find bugs. Add edge cases, ambiguous requirements, missing fields, conflicting rules, and historical defects.
The fourth mistake is not versioning prompts. A prompt is production logic when a team depends on it. Store it, review it, test it, and track changes like code.
The fifth mistake is skipping failure analysis. A score of 6 out of 10 is not the end. Ask why it failed. Did the prompt lack context? Did the source requirement lack clarity? Did the rubric punish the wrong thing? Good eval practice improves both AI output and human requirements.
Key Takeaways
LLM output evaluation is becoming a core QA skill because AI outputs are entering real delivery workflows. The safest SDETs will not be the people who blindly trust AI. They will be the people who can test it.
- LLM output evaluation checks task fit, factual grounding, and actionability.
- Prompt engineering improves answers, but evals prove whether answers meet a standard.
- PromptFoo fits prompt comparison, CI assertions, and red-team style checks.
- DeepEval fits Python teams that want test-like AI quality checks.
- For interviews, explain your rubric, dataset, automation, and human review strategy.
My suggestion for Day 5 is simple: pick one AI output your team already uses and write a five-point rubric for it. Then test 10 outputs manually. You will learn more from those 10 reviews than from watching another generic AI webinar.
FAQ
Is LLM output evaluation only for AI product teams?
No. Any team using AI to generate test cases, bug summaries, automation code, support classifications, or release notes needs some form of output evaluation. The risk starts when AI output influences real decisions.
Should QA engineers learn PromptFoo or DeepEval first?
If you prefer CLI, YAML, prompt comparison, and CI assertions, start with PromptFoo. If you are a Python SDET and want evals near code, start with DeepEval. Learn the evaluation concepts first, then choose the tool.
Can LLM-as-judge replace human review?
No. It can reduce manual effort and catch repeated patterns, but high-risk areas still need human review. Payment, healthcare, compliance, security, and production customer communication need stricter review.
What is a good first project for an SDET?
Build a requirement-to-test-case evaluator. Use 10 sample requirements, generate test cases with an LLM, score outputs with a rubric, and run the eval through PromptFoo or DeepEval in CI.
How do I explain this in an interview?
Say that you define a rubric, create a dataset with good and bad examples, run automated evals for regression, and keep human review for high-risk flows. Then give a concrete QA example like test-case generation or bug summarization.
External sources used: PromptFoo documentation, DeepEval quickstart, LangSmith evaluation concepts, GitHub repository APIs, and NPM download APIs.
🎓 Become an AI-Powered QA Engineer
Join hundreds of SDETs mastering LLM, RAG, and agent testing. Lifetime access, hands-on labs, and a job-ready portfolio.