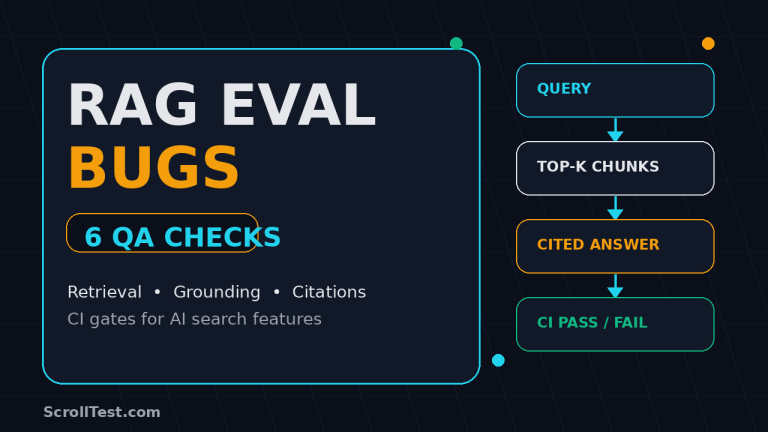
AI Testing | Testing RAG Evaluation Bugs QA Engineers Must Catch ByPromode July 30, 2026July 30, 2026
AI Testing | Test Automation | Testing LLM Testing Pipelines: DeepEval vs PromptFoo ByPromode July 28, 2026July 28, 2026
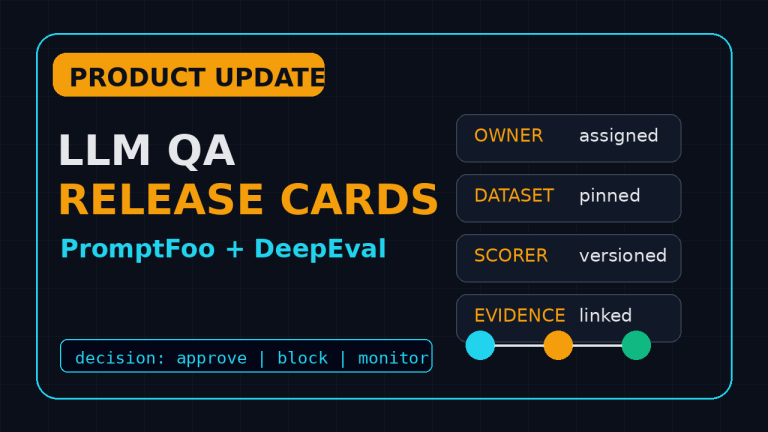
AI Testing | Test Automation | Testing LLM QA Release Cards for PromptFoo and DeepEval ByPromode July 25, 2026July 25, 2026
AI Testing | Test Automation | Testing Release-Impact Cards for QA Framework Upgrades ByPromode July 23, 2026July 23, 2026
AI Testing | Test Automation | Testing AI Agent Failing-Example Review: QA Checklist ByPromode July 22, 2026July 22, 2026
AI Testing | Testing LLM Eval Score Checklist Before You Trust DeepEval ByPromode July 20, 2026July 20, 2026
AI Testing | Test Automation | Testing AI Eval Dependency Monitoring for QA Teams ByPromode July 19, 2026July 19, 2026