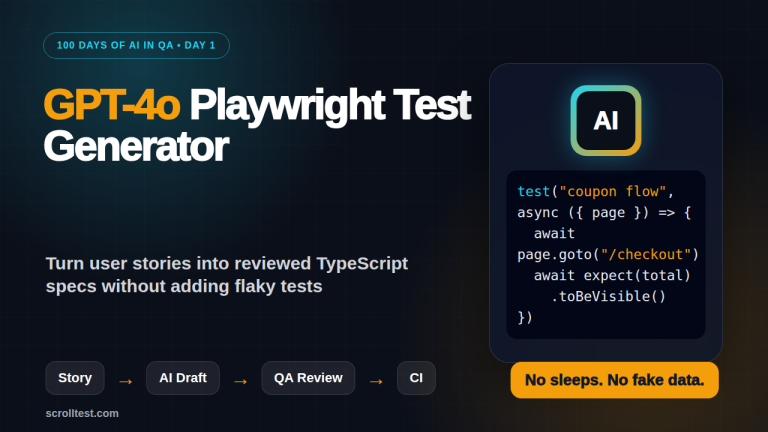
LangGraph for QA Engineers: Multi-Agent Pipelines

LangGraph for QA engineers is becoming a serious topic because single-prompt test generation breaks the moment a workflow needs memory, review, retries, and tool calls. I use LangGraph when I want an AI testing system that behaves like a pipeline, not like a chat window.
🤖 Learning AI-powered testing? Go hands-on with LLM, RAG, and AI-agent testing in the AI-Powered Testing Mastery course at The Testing Academy.
This tutorial shows a practical multi-agent test automation design: planner, generator, reviewer, executor, and defect triage nodes connected as a state graph.
Table of Contents
- Why LangGraph Fits QA Workflows
- The Multi-Agent QA Architecture
- Designing the State Model
- Building the Pipeline in Python
- Connecting Playwright Execution
- Evaluation and Guardrails
- CI/CD and Team Workflow
- India Career Context
- Key Takeaways
- FAQ
Contents
Why LangGraph for QA engineers Fits QA Workflows
Testing is already graph-shaped
A real QA workflow is not linear. Requirements are unclear, test cases branch by risk, test data fails, environments go down, and bugs need triage. LangGraph gives us a way to model that as nodes, edges, state, retries, and human checkpoints.
GitHub showed langchain-ai/langgraph at 34,118 stars and 5,738 forks when I checked it. The larger langchain-ai/langchain repository showed 138,767 stars, and PyPI Stats reported 301,642,615 downloads for the langchain package in the recent monthly window available from its API. Those numbers do not mean every QA team should adopt it tomorrow. They do mean the ecosystem is mature enough for serious prototypes.
Single agents fail under QA pressure
A single agent tries to plan, write code, run tests, interpret failures, and decide severity. That is too much responsibility. I prefer smaller agents with specific jobs and a shared state object. The planner should not execute code. The executor should not invent acceptance criteria.
- Planner reads requirements and produces risk areas.
- Generator writes Playwright tests from approved scenarios.
- Reviewer checks selectors, assertions, and data setup.
- Executor runs tests and returns traces.
- Triage maps failures to product bug, test bug, or environment issue.
For a simpler starting point, read ScrollTest’s guide on building an AI test agent with LangChain and Playwright.
LangGraph for QA engineers: The Multi-Agent QA Architecture
The five-node model
My default graph has five core nodes. Each node has a measurable output, and every edge has a reason. This is important because QA leaders do not need another black box. They need a system that explains why it created a test and why a failure matters.
- Requirement parser: extracts user journeys, roles, and constraints.
- Risk planner: ranks flows by revenue, compliance, and frequency.
- Test generator: creates Playwright TypeScript specs.
- Static reviewer: checks locators, assertions, waits, and secrets.
- Execution triage: reads reports, traces, and logs.
Where humans enter the graph
Human review is not a failure. It is a control point. I add a human checkpoint before destructive tests, before committing generated code, and before creating Jira defects. If the graph cannot explain itself, it must stop.
This maps well to MCP-style tool access too. ScrollTest’s MCP servers for testers guide explains how tool boundaries help agents call browsers, file systems, and APIs more safely.
Designing the State Model
State beats prompt soup
The biggest mistake I see is storing everything in a long prompt. Requirements, generated tests, reviewer comments, traces, and bugs become one messy string. LangGraph works better when the state is explicit and typed.
A QA state object
I keep requirements, scenarios, generated code, review notes, execution results, and triage decisions as separate fields. That makes it possible to retry one node without losing the entire run.
Building a LangGraph QA Pipeline in Python
Minimal graph structure
The code below is intentionally small. It shows the shape, not a production wrapper. In a real system I add model calls, structured output validation, trace storage, and a human approval queue.
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
class QAState(TypedDict):
requirement: str
scenarios: List[str]
test_code: str
review_notes: List[str]
run_status: str
triage: str
def plan_tests(state: QAState) -> QAState:
requirement = state['requirement']
state['scenarios'] = [
f'happy path for: {requirement}',
f'negative path for: {requirement}',
'accessibility check for primary CTA'
]
return state
def generate_playwright(state: QAState) -> QAState:
state['test_code'] = "import { test, expect } from '@playwright/test';\n" + "test('checkout happy path', async ({ page }) => {\n" + " await page.goto('/checkout');\n" + " await page.getByRole('button', { name: 'Pay now' }).click();\n" + " await expect(page.getByText('Payment successful')).toBeVisible();\n" + "});"
return state
def review_code(state: QAState) -> QAState:
notes = []
if 'waitForTimeout' in state['test_code']:
notes.append('Reject: hard wait found')
if 'getByRole' not in state['test_code']:
notes.append('Improve locator strategy')
state['review_notes'] = notes
return state
def route_after_review(state: QAState) -> str:
return 'execute' if not state['review_notes'] else 'human_review'
def execute_tests(state: QAState) -> QAState:
state['run_status'] = 'simulated-pass'
return state
def human_review(state: QAState) -> QAState:
state['triage'] = 'needs QA approval before execution'
return state
graph = StateGraph(QAState)
graph.add_node('plan', plan_tests)
graph.add_node('generate', generate_playwright)
graph.add_node('review', review_code)
graph.add_node('execute', execute_tests)
graph.add_node('human_review', human_review)
graph.set_entry_point('plan')
graph.add_edge('plan', 'generate')
graph.add_edge('generate', 'review')
graph.add_conditional_edges('review', route_after_review, {
'execute': 'execute',
'human_review': 'human_review'
})
graph.add_edge('execute', END)
graph.add_edge('human_review', END)
app = graph.compile()
result = app.invoke({
'requirement': 'user can pay for an order with UPI',
'scenarios': [],
'test_code': '',
'review_notes': [],
'run_status': '',
'triage': ''
})
print(result)Why this pattern scales
This graph lets you replace one function at a time. You can start with deterministic Python functions, then add LLM calls only where judgment is needed. That keeps costs lower and debugging easier.
Connecting Playwright Execution
Run generated tests like normal tests
I do not want generated tests living in a separate toy runner. Once code passes review, write it to a normal Playwright spec file and run the same CI command the team already trusts.
# Example CI command generated by the executor node
npm ci
npx playwright install --with-deps chromium
npx playwright test tests/generated/checkout.spec.ts --reporter=json,line
Collect traces and JSON reports
The executor node should return structured evidence: exit code, failing test title, screenshot path, trace path, console errors, and network failures. The triage node should never guess from a one-line stack trace.
playwright-report/index.htmlfor human debuggingtest-results/**/*.zipfor tracesresults.jsonfor agent-readable status- Console logs and API error summaries
🚀 Build Real AI Testing Skills
Stop testing AI by guesswork. Learn DeepEval, RAG evaluation, and agent testing with guided projects.
Evaluation and Guardrails for LangGraph for QA engineers
Score the output before execution
Every generated test should pass a static review. I check for test isolation, locator quality, assertions, secrets, hard waits, and data cleanup. This is where frameworks like DeepEval or PromptFoo can help evaluate agent outputs against rubrics, but simple deterministic checks catch many bad cases.
Use a rubric
A 10-point rubric makes review conversations concrete. Give 2 points for locator quality, 2 for meaningful assertions, 2 for data setup, 2 for maintainability, and 2 for risk coverage. Anything below 8 should not enter the repo automatically.
- Reject hard waits like
waitForTimeout(5000). - Reject selectors based only on CSS classes.
- Require at least one business assertion per test.
- Require cleanup for created users, orders, or payments.
- Store the original requirement next to the generated spec.
CI/CD and Team Workflow
Do not auto-merge generated tests
The graph can open pull requests. It should not merge them. Generated automation changes the release signal, and release signals need ownership. A senior SDET or module owner should approve the test before it becomes part of required CI.
Make the pipeline observable
Log model input hashes, output versions, reviewer notes, execution commands, and run IDs. When a test fails two weeks later, you need to know which requirement generated it and which reviewer approved it.
If your team is moving from manual regression to agent-assisted automation, combine this with ScrollTest’s practical 90-day roadmap from manual tester to AI engineer.
India Career Context: Why This Skill Pays
From script writer to automation architect
Many QA engineers in India still get evaluated on test case count and automation percentage. That is changing. Product companies want people who can design systems that reduce cycle time and protect quality. LangGraph-style pipelines show architecture thinking, not only scripting.
A manual tester moving into automation can start with Playwright. A mid-level SDET can add API contracts and CI. A senior SDET targeting ₹25-40 LPA roles should understand agent workflows, evaluation, observability, and security boundaries. This is the kind of portfolio project that stands out in interviews.
Portfolio project idea
Build a public demo that reads a small PRD, creates 8 scenarios, generates 3 Playwright tests, rejects 1 bad test, executes 2 safe tests, and prints a triage report. Keep the scope small and the evidence strong.
Key Takeaways: LangGraph for QA engineers Need Engineering Discipline
LangGraph for QA engineers is not about replacing QA engineers with a bot. It is about giving SDETs a programmable workflow for planning, generation, review, execution, and triage.
- Use LangGraph when the QA workflow needs state, branches, and retries.
- Split planner, generator, reviewer, executor, and triage responsibilities.
- Run generated tests through normal Playwright and CI commands.
- Add human checkpoints before destructive tests and repo changes.
- Measure quality with a rubric, not only pass/fail status.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
Cost control
Agent pipelines can become expensive if every node calls a large model. I start with rules for parsing, static checks, and command execution. I reserve model calls for requirement interpretation and failure triage. That design keeps the system predictable and easier to debug during CI failures.
For a team of 12 SDETs, the best first win is not full autonomy. It is cutting review time for generated test drafts from 30 minutes to 10 minutes while keeping the final approval with an owner.
FAQ
Is LangGraph required for AI test automation?
No. Start with simple scripts if your workflow is linear. Use LangGraph when you need branching, state, retries, and review loops.
Can LangGraph run Playwright directly?
LangGraph controls the workflow. A node can call Playwright through Python subprocesses, Node commands, MCP tools, or an internal runner.
Should generated tests be committed automatically?
I do not recommend auto-merge. Let the graph open a pull request with evidence, then require human review.
What should QA engineers learn first?
Learn Playwright basics, Python typing, API testing, and CI. Then add LangGraph for orchestration and agent control.
🎓 Become an AI-Powered QA Engineer
Join hundreds of SDETs mastering LLM, RAG, and agent testing. Lifetime access, hands-on labs, and a job-ready portfolio.